












AMD a récemment introduit sa nouvelle architecture Zen 5 avec les nouveaux processeurs AMD Ryzen 9000 au nom de code Granite Ridge. Cette architecture représente une évolution significative de la précédente génération. Bien que cette nouvelle version n’abandonne pas les fondations posées par les architectures antérieures, elle apporte des améliorations substantielles, notamment des gains à deux chiffres en termes de performances par cycle d’horloge (IPC), du moins selon AMD. En effet, il est annoncé +16%, mais en comparant un R9 9950X à un R7 7700X à 4 GHz. Zen 5 vise à optimiser la performance tout en maintenant un équilibre dans le design du processeur.

Le développement de Zen 5 s’est concentré sur l’amélioration des performances aussi bien en Single qu’en Multi, une priorité logique après les optimisations de cache introduites avec Zen 4. Zen 5 introduit une nouvelle base microarchitecturale qui servira de point de départ pour les futures évolutions comme le prochain Zen 6.
AMD Zen 5 : améliorations du Front-End
AMD poursuit l’évolution de son architecture CPU avec Zen 5, en mettant un accent particulier sur les améliorations du Front-End, la partie du processeur responsable de préparer les instructions pour les unités d’exécution du Back-End. Ces optimisations visent à maximiser l’efficacité du traitement des instructions, offrant ainsi des performances accrues dans les applications modernes.
L’une des innovations majeures de Zen 5 réside dans l’intégration d’un double pipeline de décodage. Cette technologie, déjà utilisée par le concurrent Intel, permet à AMD de traiter deux flux d’instructions indépendants en parallèle. Ce choix se révèle particulièrement avantageux dans les scénarios où le processeur doit gérer plusieurs branchements conditionnels spéculatifs ou le multithreading simultané (SMT). De plus, les buffers accueillant les instructions décodées ont été agrandis, avec un OpCache 33 % plus grand qu’auparavant, capable de traiter directement les instructions au lieu de micro-instructions, ce qui améliore la densité et l’efficacité du processus de décodage. Au final, Zen 5 peut décoder jusqu’à 12 instructions par cycle, une capacité qui marque une nette avancée par rapport aux générations précédentes.
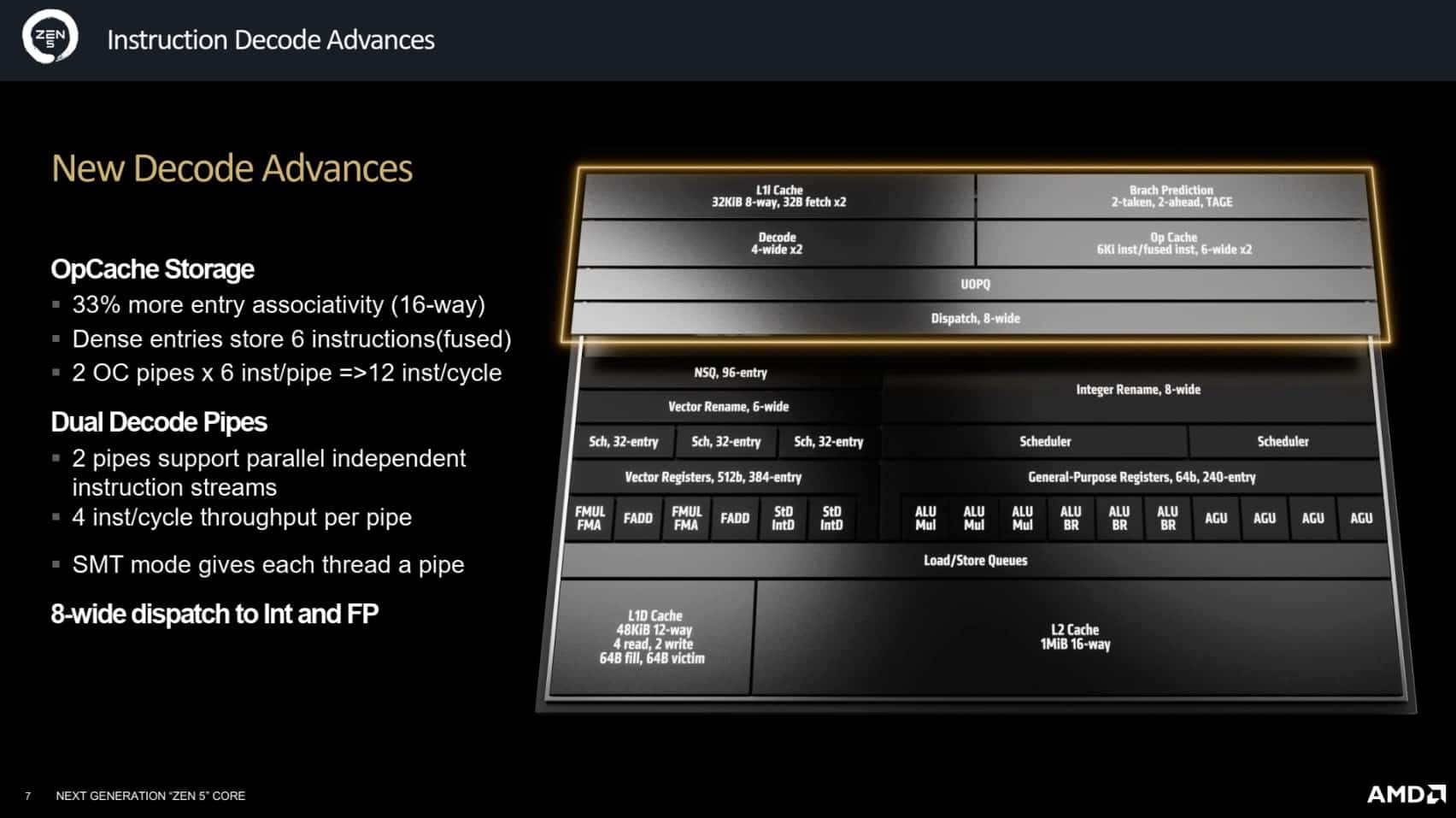
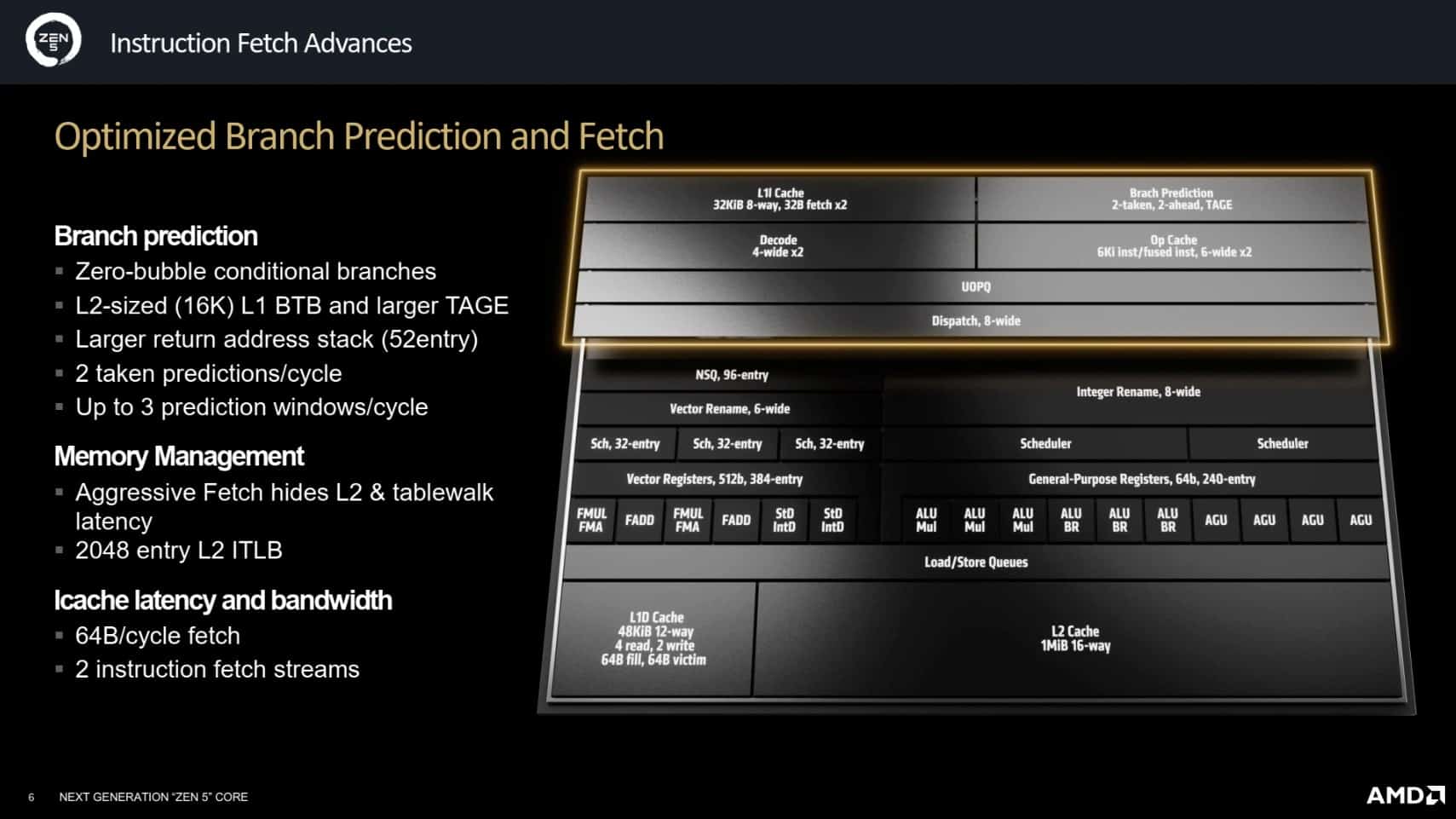
La prédiction de branchement est un autre aspect clé du Front-End qui a bénéficié d’améliorations significatives dans Zen 5. Cette technique permet d’anticiper la direction des branchements dans le code pour continuer à exécuter des instructions sans attendre les résultats intermédiaires. Zen 5 introduit un cache L1 d’historique des branchements (BTB) élargi à 16K entrées, une capacité typique d’un cache L2, tandis que le cache L2 associé reste plus modeste avec 8K entrées. Cette configuration a été choisie pour permettre à Zen 5 de prédire deux branchements par cycle, nécessitant une augmentation des capacités de prédiction et de décodage.
D’autres optimisations incluent l’agrandissement de la pile des retours d’adresses, utilisée pour gérer les sauts de fin de routine, qui passe à 52 entrées. Bien que la prédiction des branchements conditionnels ait été optimisée pour ne pas ajouter de latence supplémentaire, une légère augmentation de la latence en cas de mauvaise prédiction a été observée, avec une moyenne officieuse de 13 cycles.
Back-End et AVX-512
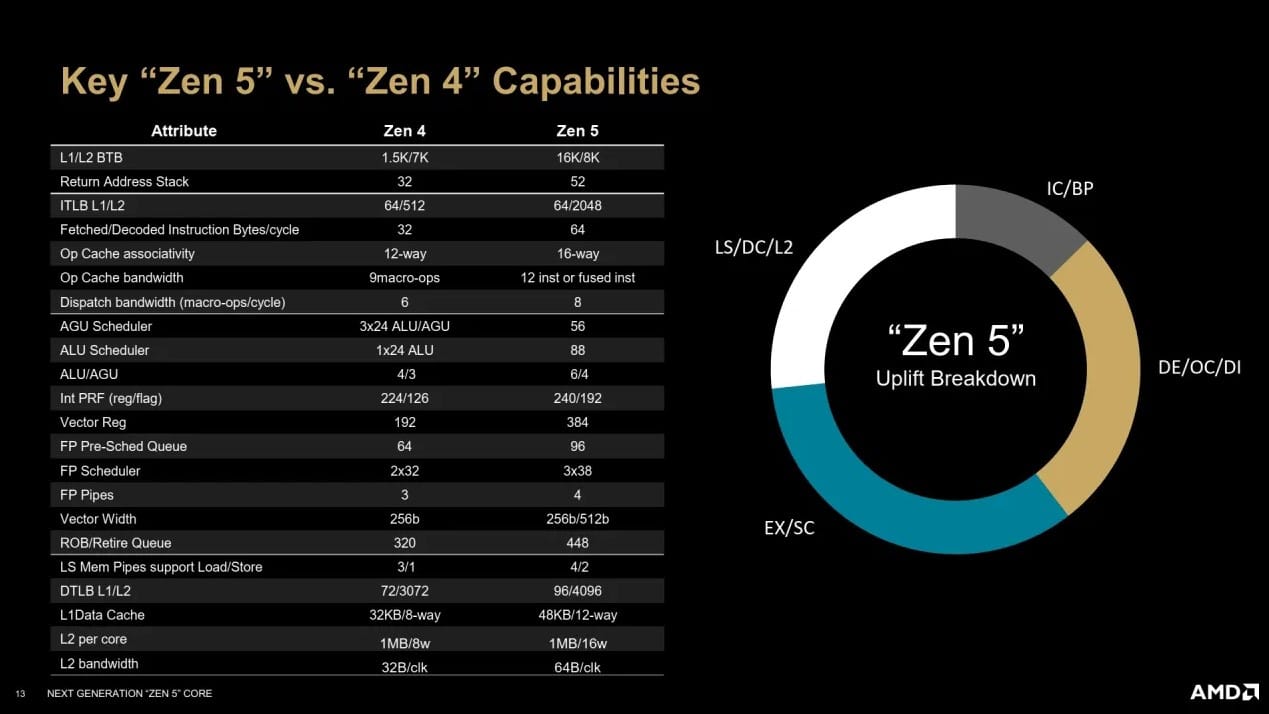
AMD continue d’innover avec sa nouvelle architecture Zen 5, en mettant l’accent sur l’amélioration des performances grâce à des changements significatifs dans le traitement des micro-ops. Ces améliorations visent à maximiser le parallélisme, augmentant ainsi l’efficacité du processeur. Zen 5 a été conçue pour tirer le meilleur parti des micro-ops décodées et prédites, en les exécutant simultanément pour optimiser les performances. Pour y parvenir, la société a augmenté la taille du ReOrder Buffer (ROB), passant de 320 à 448 entrées. Cela permet de traiter un plus grand nombre de micro-ops par cycle, améliorant ainsi le fameux IPC (instructions par cycle).

Zen 5 introduit également des modifications dans la gestion des unités de traitement. AMD a unifié le scheduler, qui attribue les micro-ops aux unités de calcul, en simplifiant sa structure avec une matrice d’âge unique. Cette approche réduit les risques de blocages (stalls) et permet une distribution plus efficace des tâches. De plus, deux nouvelles unités arithmétiques et logiques (ALU) ainsi qu’une unité de génération d’adresses (AGU) ont été ajoutées, élargissant le pipeline à 10 ports.
Le pipeline flottant, bien que conservant sa largeur de 6 ports, a été amélioré avec l’intégration complète des unités AVX-512, configurables en mode 256-bit ou 512-bit. Cette amélioration est l’un des principaux progrès de Zen 5, permettant des calculs plus rapides et plus efficaces, en particulier dans les scénarios nécessitant des opérations flottantes complexes.

Gestion du cache
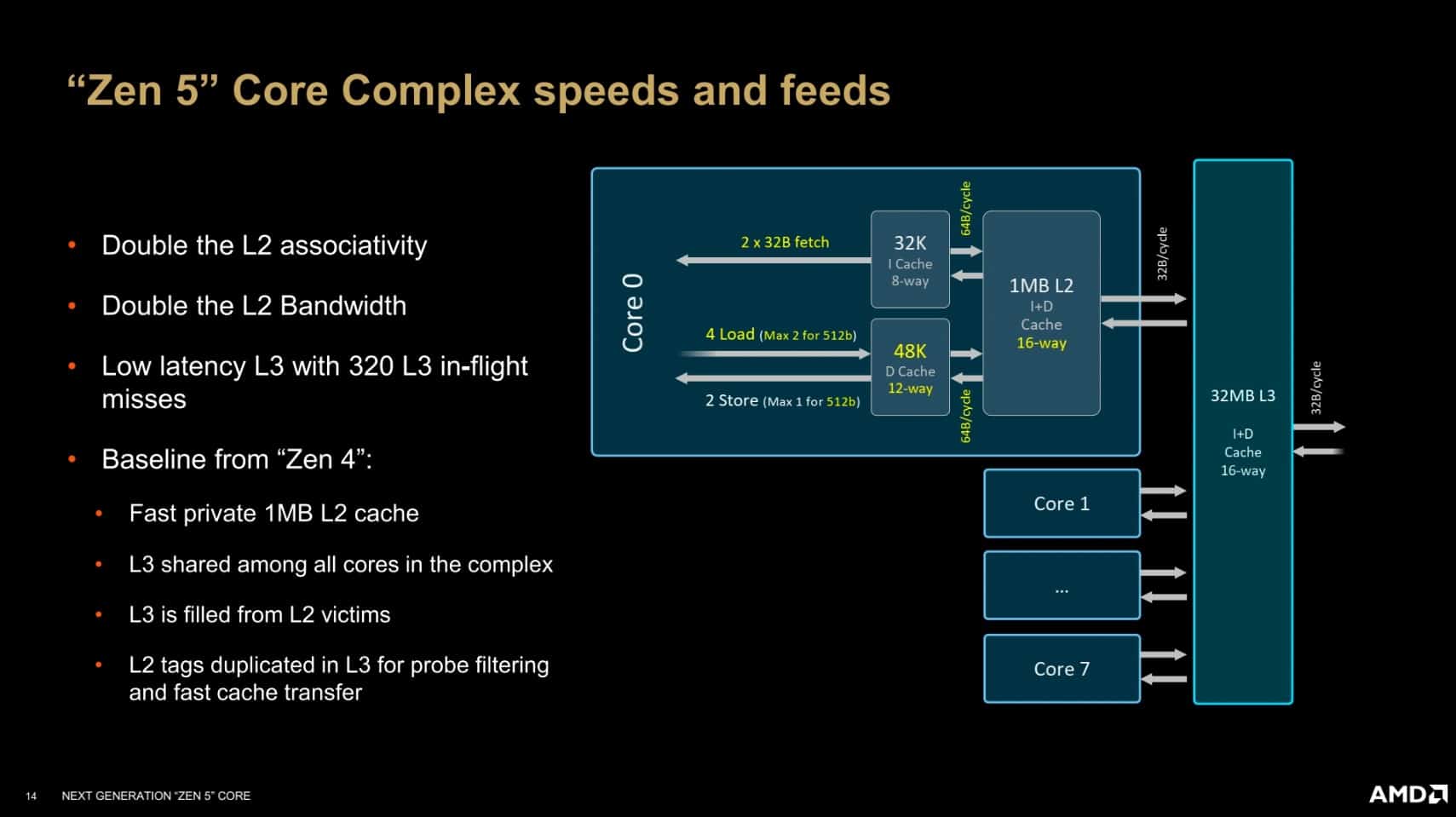
Avec l’architecture Zen 5, AMD ne se contente pas d’augmenter la puissance de calcul de ses processeurs, mais renforce également le sous-système mémoire pour assurer une performance optimale. Ces ajustements visent à équilibrer les différentes composantes du processeur pour éviter les goulets d’étranglement et maximiser l’efficacité globale. L’une des principales évolutions de Zen 5 concerne le cache de données de niveau 1 (L1D), qui passe à 48 Kio, réparti en 12 voies, tout en maintenant une latence de 4 cycles. Cette augmentation vise à répondre aux besoins accrus de bande passante générés par les nouvelles capacités de calcul du processeur. Le cache de niveau 2 (L2) reste quant à lui à 1 Mio par cœur. Le cache de niveau 3 (L3) dans Zen 5 est conçu pour s’adapter à différents types de besoins, avec une capacité pouvant varier entre 8 et 32 Mio selon s’il s’agit d’une configuration pour desktop, mobile ou encore serveur.
Les TLB (Translation Lookaside Buffers), qui jouent un rôle crucial dans la gestion des pages de mémoire, ont également été améliorés. Le TLB de niveau 1 (L1) pour les pages de données dispose désormais de 96 entrées, tandis que le TLB de niveau 2 (L2) en offre 4 000, une augmentation significative qui améliore la rapidité et l’efficacité de la gestion des pages mémoire. Pour les instructions, le TLB de niveau 2 (L2) a été étendu à 2 048 entrées, renforçant ainsi la capacité de gestion des processus complexes. Afin de répondre aux besoins de traitement du double décodeur et des nouvelles capacités AVX-512, la bande passante des caches L1-I et L2 a été doublée. Cette augmentation permet de maintenir un flux de données constant et d’éviter les goulots d’étranglement qui pourraient limiter les performances des unités de calcul.

Un design homogène pour les nouveaux SoCs
Avec l’architecture Zen 5, AMD continue de peaufiner son approche en renforçant l’intégration des extensions du jeu d’instruction x86, consolidant ainsi ses performances et sa compatibilité avec les technologies les plus récentes. Zen 5 voit un support encore plus large de l’AVX-512, un ensemble d’instructions qui permet d’accélérer les calculs complexes, particulièrement utile dans les domaines scientifiques, le traitement d’image, et l’intelligence artificielle. En plus de cela, Zen 5 introduit de nouvelles instructions de streaming qui permettent aux développeurs de stocker des valeurs directement en mémoire sans passer par les caches. Cette fonctionnalité est particulièrement utile lorsque le programmeur sait que les données ne seront pas réutilisées immédiatement, optimisant ainsi l’utilisation des ressources du CPU et évitant la pollution des caches.
AMD introduit également dans son architecture Zen 5 la capacité d’isoler les compteurs hardware lorsqu’on utilise des machines virtuelles. Les compteurs hardware sont des mécanismes essentiels pour collecter des statistiques sur l’état du processeur pendant l’exécution des tâches, et cette isolation assure que les environnements virtuels puissent fonctionner sans interférences, offrant ainsi une sécurité et une performance accrues dans des contextes où la virtualisation est essentielle.


Bien que ce ne soit pas l’élément central pour tous les utilisateurs, Zen 5 comprend aussi des interfaces avancées pour mieux gérer l’intégration de cœurs hétérogènes, une technologie où différents types de cœurs sont combinés pour maximiser l’efficacité énergétique et la performance. Cette capacité pourrait être particulièrement utile dans les configurations futures où l’efficacité est cruciale, comme les ordinateurs portables ou les serveurs à haute densité.
Comment ça se passe sous le die ?
Comme pour les précédentes générations, Zen 5 s’organise autour de Core Complexes (CCX), avec une bande passante inchangée de 32 octets par cycle pour le cache L3, partagé entre tous les cœurs du cluster. Le cache L3 reste également interfacé avec une bande passante de 32 octets en lecture et 16 octets en écriture. Cette configuration vise à maintenir une compatibilité avec les anciens designs en chiplets, mais pourrait limiter les performances des unités vectorielles AVX-512, dont les besoins en bande passante sont plus élevés que ce que le L3 peut offrir.
Les Ryzen 9000 intègrent un ou deux CCD épaulés par un IOD (die d’entrées/sorties). Contrairement à son principal concurrent, AMD opte pour une structure homogène où tous les cœurs sont basés sur la même architecture et le même procédé de gravure. Pour réduire les coûts, AMD réutilise même le design du CIOD (Contrôleur d’Entrées/Sorties) de la génération Zen 4, assurant une transition plus économique vers la nouvelle génération.
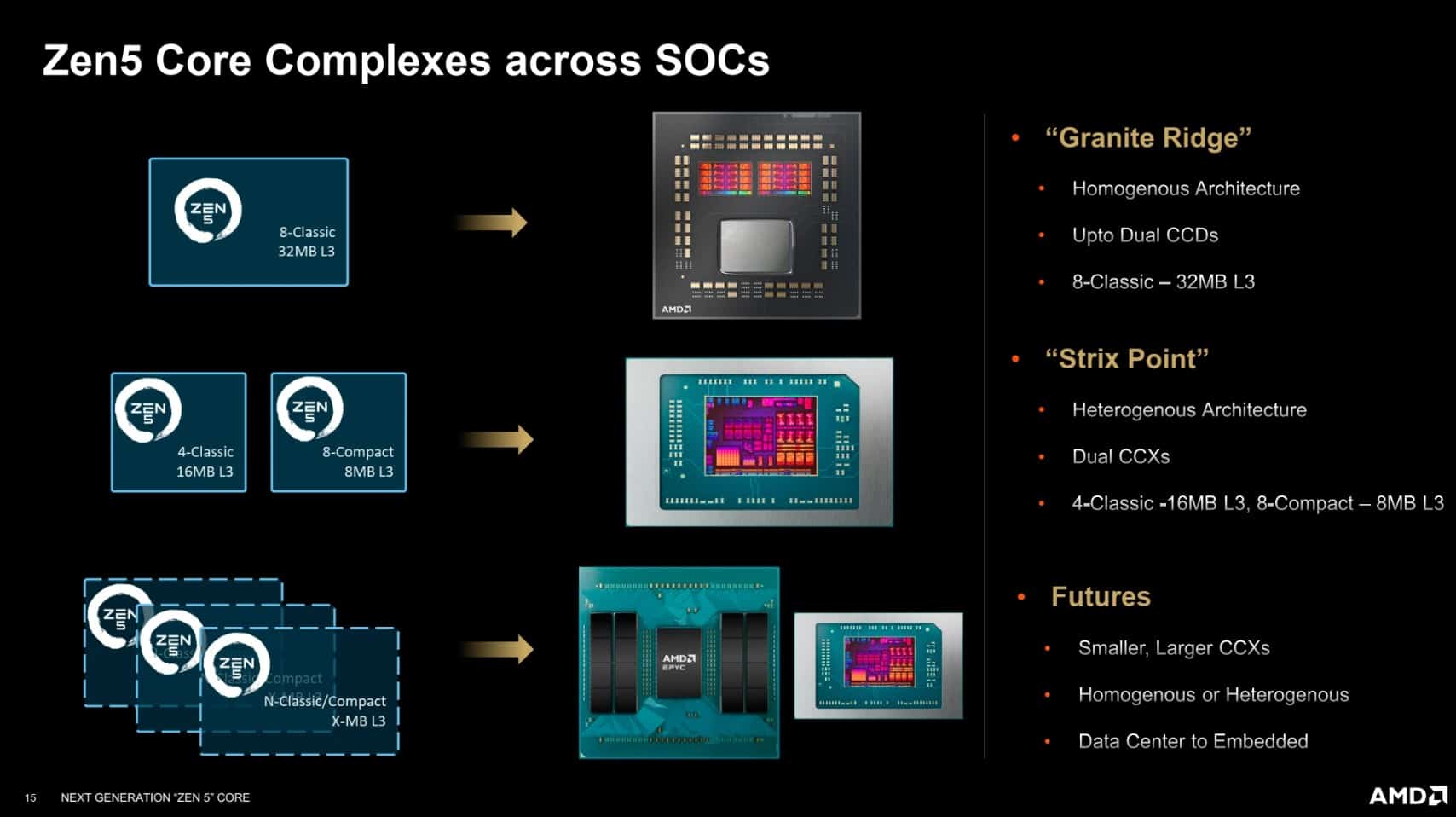
Chaque CCD de Zen 5 conserve un maximum de 32 Mio de cache L3 intégré par puce, avec une option d’extension jusqu’à 96 Mio dans les futures versions X3D, bien que celles-ci n’aient pas encore été officiellement annoncées, mais seulement teasés. Cette capacité augmentée du cache est particulièrement attendue pour améliorer les performances dans des tâches exigeantes en données.




